DNS servers are down, Internet service severely disrupted in the US
![]() 2 min. read
2 min. read
![]() Published on
Published on
Share this article

Read our disclosure page to find out how can you help Windows Report sustain the editorial team Read more
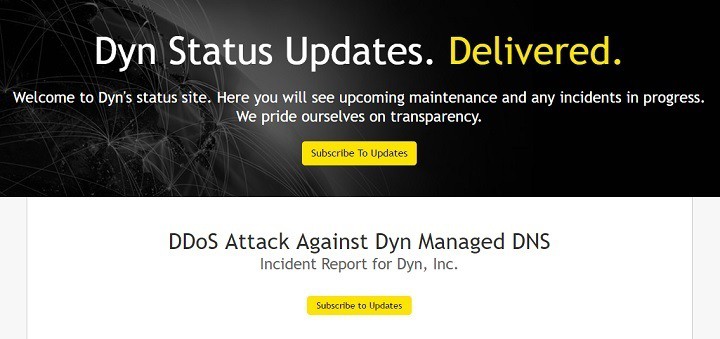
At this moment, millions of Windows users cannot access popular platforms such as Twitter, Reddit, Github, Amazon and others due to a series of DDoS attacks against Dyn. Distributed Denial of Service (DDoS) attacks operate by overwhelming a website by traffic from many sources. Actually, this is a very common modus operandi for digital attacks.
According to Dyn’s official statement, the attack is mainly impacting US East and is affecting DNS customers in this region. The company’s engineers are still working on mitigating this DNS issue. Although the attack’s intensity has considerably diminished thanks to Dyn’s efforts, it still affects a huge number of users.
When Windows users first noticed this issue, they thought there was a problem with their computers. Users report that the error message “DNS Server isn’t responding” appears on the screen whenever they try to access particular websites. Rest assured, there is nothing wrong with your Windows computer.
As of the past hour, DynDNS got attacked and DDoSed. It’s one of the biggest DNS providers, so naturally that impacts a lot of internet access to seemingly random sites, including Runescape. Therefore, I suggest changing to Google’s Public DNS for now. The DNS addresses are 8.8.8.8 and 8.8.4.4. For more details on how to change your DNS, read Google’s explanation.
This solution works and allows you to connect to the websites of your choice, but as another users points out, the best thing to do is wait. Connecting to a public DNS server, such as Google’s, might actually be the point of such an attack: make people use less secure connections.
Meanwhile, if your DNS is still unavailable, try using one of these workarounds and see is these solutions fix the problem for you.
RELATED STORIES YOU NEED TO CHECK OUT: